Cogito v1 Preview
Introducing IDA as a path to general superintelligence
Takeaways
- We are releasing the strongest LLMs of sizes 3B, 8B, 14B, 32B and 70B under open license. Each model outperforms the best available open models of the same size, including counterparts from LLaMA, DeepSeek, and Qwen, across most standard benchmarks. In particular, the 70B model also outperforms the newly released Llama 4 109B MoE model.
- The LLMs are trained using Iterated Distillation and Amplification (IDA) - a scalable and efficient alignment strategy for general superintelligence using iterative self-improvement.
- Each model can answer directly (standard LLM), or self-reflect before answering (like reasoning models).1
- We plan to release larger models, including 109B, 400B, 671B, in the coming weeks / months, as well as improved checkpoints for each of these model sizes.
You can download the models on Huggingface or Ollama, or use them directly through the API on Fireworks AI or Together AI.
The Path to General Superintelligence
AlphaGo, followed by many other game-playing AIs, demonstrated that AI systems can achieve superhuman performance in narrow domains. When we study these superintelligent systems, we find two key ingredients enabled this breakthrough:
- Advanced Reasoning: The capacity to derive significantly improved solutions with increased compute.
- Iterative Self-Improvement: The capacity to refine intelligence in a manner not strictly bounded by an external overseer's capabilities.
Recent research in LLMs has made significant progress in reasoning capabilities. However, current LLM training paradigms inherently limit intelligence to the capabilities of their overseers:
- Smaller models inherit the upper bound of intelligence from the larger models they're distilled from.
- The largest models, typically trained on human-curated data, remain constrained by human overseers' intellectual capabilities.
Although improved reasoning alone may bring us closer to Artificial General Intelligence (AGI), achieving general superintelligence requires surpassing these inherent overseer limitations.
We present an initial approach toward overcoming these constraints via iterative self-improvement in LLMs, integrated with advanced reasoning. We believe this methodology may offer a structured and efficient path for moving beyond current intelligence limits.
Iterated Distillation and Amplification
We train LLMs through Iterated Distillation and Amplification (IDA) (1, 2) - an alignment strategy which is not upper bounded by overseer intelligence.
Concretely, each iteration involves the following steps:
- Step 1 (Amplification) - Creating higher intelligence capabilities via subroutines that usually involve more computation.2
- Step 2 (Distillation) - Distilling the higher intelligence back to the model's parameters to internalize the amplified capability.
We use more computation to let the model arrive at a better solution, and then distill the expensive thinking process to the model's own parameters. As the LLM improves in intelligence, the thinking process itself becomes more powerful.
By repeating these two steps, each cycle builds upon the progress of the previous iteration. This iterative framework creates a positive feedback loop in which the model's capabilities are increasingly determined by computational resources and the efficacy of the amplification-distillation process, rather than by the original overseer's limitations.
Our initial experiments indicate that this approach can systematically improve model performance and generalize to most tasks.3 In addition, IDA is both more efficient time-wise, and more scalable, than other popular approaches like RLHF and distillation from larger models.
As an example, the Cogito models were developed by a small team in approximately 75 days. In terms of performance, the 70B model trained using IDA outperforms Llama 3.3 70B model distilled from the 405B Llama 3 model as well as the 109B Llama 4 Scout model distilled from the 2T parameter Llama 4 Behemoth model.
Model Details
We are releasing early checkpoints of models in sizes 3B, 8B, 14B, 32B and 70B trained using this methodology, starting from pretrained Llama / Qwen base checkpoints.
- The models are optimized for coding, function calling, and agentic use cases.
- Each model can function in a standard mode as well as a reasoning mode.
- Unlike most reasoning models, we have not optimized for very long reasoning chains.4
We expect to release larger models (MoEs of sizes 109B, 400B, 671B) as well as updated checkpoints in the coming weeks / months.
Evaluation
We compare our models against the state of the art size equivalent models in direct mode as well as the reasoning mode. For the direct mode, we compare against Llama / Qwen instruct counterparts. For reasoning, we use Deepseek's R1 distilled counterparts / Qwen's QwQ model.
The benchmarks shown here are industry-standard and illustrate IDA's effectiveness.5
(Note - While these benchmarks provide a useful signal, they do not fully capture real-world performance. In practice, benchmark scores only loosely correlate with how well a model serves a user's needs. That said, our models have been tested across multiple well-known evaluations and consistently perform well.
Ultimately, the best evals are the ones closest to user's needs. We are confident that our models will stand up to such real-world evaluations and deliver strong results in practice.)
Smaller Models - 3B and 8B
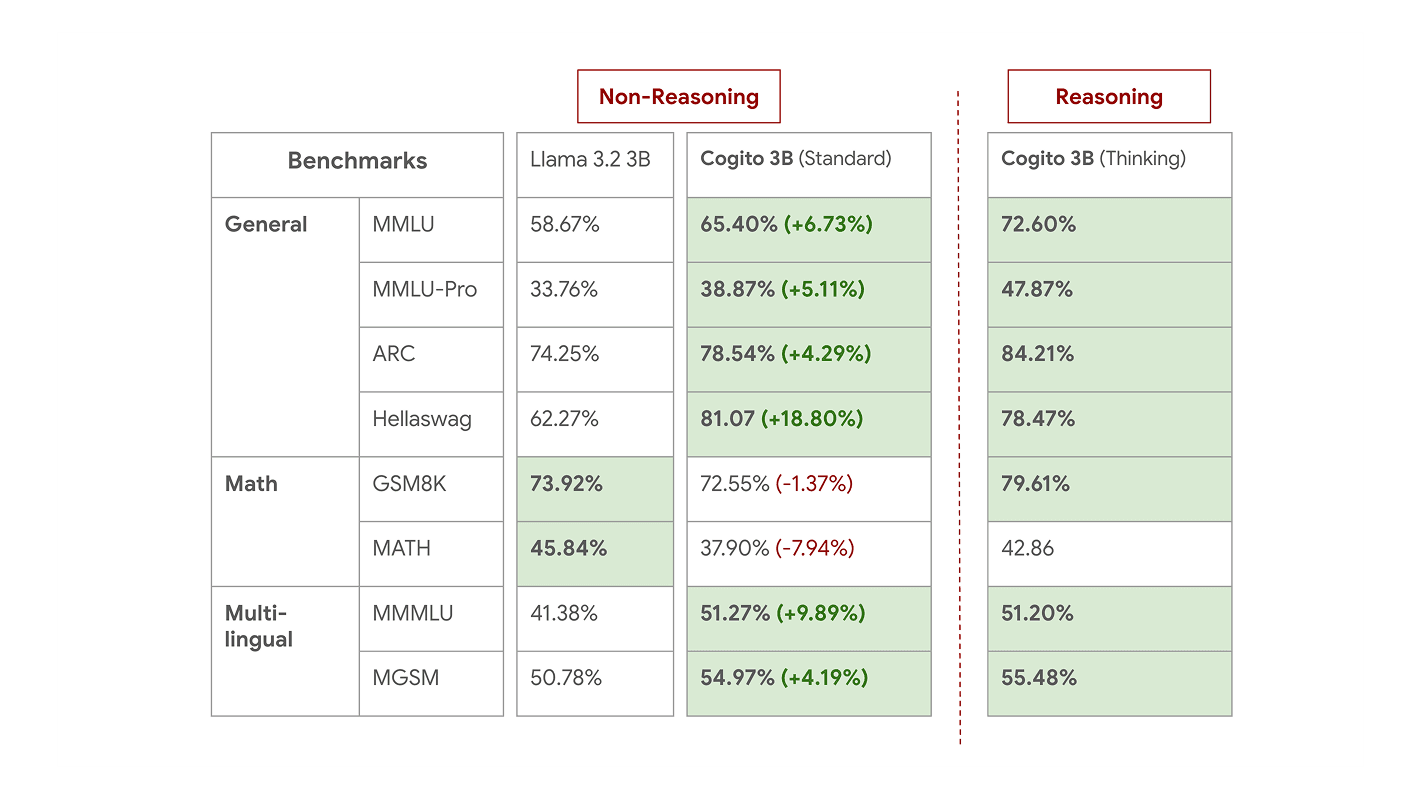
Performance of 3B models

Performance of 8B models

Tool Calling for smaller models6
Medium Models - 14B and 32B

Performance of 14B models

Performance of 32B models
Larger Models - 70B

Performance of 70B models
Livebench Scores

Livebench Global Average
Looking Ahead
Iterated Distillation and Amplification is a promising alignment technique for self-improvement. Currently, we're still in the early stages of this scaling curve, having used only a fraction of compute typically reserved for traditional large language model post/continued training.
Moving forward, we're investigating complementary post-training approaches for self-improvement. Our next release will feature updated checkpoints for each model size (3B to 70B), with extended training periods, as well as larger models in the coming weeks and months.
All models will be open source.
About Deep Cogito
At Deep Cogito, we are building general superintelligence. Achieving this requires scientific breakthroughs - like advanced reasoning and iterative self-improvement - not only to match human-level abilities but also to uncover entirely new capabilities we have yet to imagine.
We're headquartered in San Francisco and are well-funded by some of the best VCs in AI. We are bringing together the world's top engineers and researchers to pioneer this future.
If our mission resonates with you, send us an email at join@deepcogito.com with your resume and a brief paragraph detailing your previous LLM or AI infrastructure experience.
Acknowledgements
This work was supported by multiple excellent teams and projects that we'd like to thank - Llama Team, Qwen Team, Huggingface, RunPod, Fireworks AI, Together AI, Ollama, Nebius.
1 This is similar to Claude 3.7, where you can pick when you want the model to answer normally and when you want it to think longer before answering.
2 These are similar to techniques like using CoT, answer verification, sampling multiple responses, etc.
3 This methodology is not restricted to verifiable domains like coding and mathematics, but used for all domains.
4 This decision is because of multiple factors: In real world tasks (outside of academic/industry benchmarks) most users do not want to wait for a significant amount of tokens before the actual answer. Secondly, smaller reasoning chains are easily distilled back to the model's parameters in the next step. Lastly, the thinking process after IDA is more powerful than traditional reasoning and shouldn't need more tokens.
5 The test sets of these benchmarks were removed from all training data using string matching.
6 These results are for (native) tool calling. Llama 3.2 3B does not support tool calling natively as per BFCL, whereas Llama 3.1 8B does support it. If we rely on traditional prompt-based interactions to produce function calls in the desired format (as opposed to a dedicated tools section), then the difference between Cogito and Llama models is significantly less. As such, most of the improvements in tool calling are primarily because Llama models aren't post-trained for it properly (as opposed to improved model capabilities alone).

